| This post was kindly contributed by The SAS Dummy - go there to comment and to read the full post. |
Regular expressions provide a powerful method to find patterns in a string of text. However, the syntax for regular expressions is somewhat cryptic and difficult to devise. This is why, by my reckoning, approximately 97% of the regular expressions used in code today were copied and pasted from somewhere else. (Who knows who the original authors were? Some experts believe they were copied from ancient cave paintings in New Mexico.)
You can use regular expressions in your SAS programs, via the PRX* family of functions. These include PRXPARSE and PRXMATCH, among others. The classic example for regular expressions is to validate and standardize data values that might have been entered in different ways, such as a phone number or a zip code (with or without the plus-4 notation).
In this post I’ll present another, less-trodden example. It’s a regular expression that validates the syntax of a SAS variable name. (Now, I’m talking about the regular old traditional SAS variable names, and not those abominations that you can use with OPTIONS VALIDVARNAME=ANY.)
SAS variable names, as you know, can be 1 to 32 characters long, begin with a letter or underscore, and then contain letters, numbers, or underscores in any combination after that. If all you need is a way to validate such names, stop reading here and go learn about the NVALID function, which does exactly this. But if you want to learn a little bit about regular expressions, read on.
The following program shows the regular expression used in context:
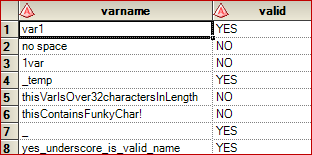
data vars (keep=varname valid); length varname $ 50; input varname 1-50 ; re = prxparse('/^(?=.{1,32}$)([a-zA-Z_][a-zA-Z0-9_]*)$/'); pos = prxmatch(re, trim(varname)); valid = ifc(pos>0, "YES","NO"); cards; var1 no space 1var _temp thisVarIsOver32charactersInLength thisContainsFunkyChar! _ yes_underscore_is_valid_name run;
And the results:
Here’s a closer look at the regular expression in “diagram” form, lightly annotated. (This reminds me a little of how we used to diagram sentences in 4th grade. Does anybody do that anymore?)

Among the more interesting aspects of this expression is the lookahead portion, which checks that the value is between 1 and 32 characters right out of the gate. If that test fails, the expression fails to match immediately. Of course, you could use the LENGTHN function to check that, but it’s nice to include all of the tests in a single expression. I mean, if you’re going to write a cryptic expression, you might as well go all the way.
Unless you live an alternate reality where normal text looks like cartoon-style swear words, there really isn’t much that’s “regular” about regular expressions. But they are extremely powerful as a data validation and cleansing tool, and they exist in just about every programming language, so it’s a transferable skill. If you take the time to learn how to use them effectively, it’s sure to pay off.
| This post was kindly contributed by The SAS Dummy - go there to comment and to read the full post. |