I recently paddled in a boat race, and was wondering how I did compared to all the other paddlers. And being a Graph Guy, I decided I should find a cool way to graph the data … Here’s some background information … There’s a great organization calle…
Category: SAS
Most popular international destination, from each US state
Orbitz recently published a map showing the most popular international travel destination for each of the 50 US states. It was an interesting map … but of course, me being the Graph Guy, I had to pick it apart and create my own version. Follow along,…
The ‘virtual wall’ along the US/Mexican border
Recent news reports indicate that the number of illegal immigrants apprehended along the US/Mexican border has dropped significantly since Trump took office. So, even though Trump hasn’t had time to build a physical wall, perhaps there’s a virtual wall…
ggformula: another option for teaching graphics in R to beginners
A previous entry (http://sas-and-r.blogspot.com/2017/07/options-for-teaching-r-to-beginners.html) describes an approach to teaching graphics in R that also “get[s] students doing powerful things quickly”, as David Robinson suggested.
In this guest blog entry, Randall Pruim offers an alternative way based on a different formula interface. Here’s Randall:
For a number of years I and several of my colleagues have been teaching R to beginners using an approach that includes a combination of
- the
latticepackage for graphics, - several functions from the
statspackage for modeling (e.g.,lm(), t.test()), and - the
mosaicpackage for numerical summaries and for smoothing over edge cases and inconsistencies in the other two components.
Important in this approach is the syntactic similarity that the following “formula template” brings to all of these operations.
goal ( y ~ x , data = mydata, … )
Many data analysis operations can be executed by filling in four pieces of information (goal, y, x, and mydata) with the appropriate information for the desired task. This allows students to become fluent quickly with a powerful, coherent toolkit for data analysis.
Trouble in paradise
As the earlier post noted, the use of
Trouble in paradise
As the earlier post noted, the use of
lattice has some drawbacks. While basic graphs like histograms, boxplots, scatterplots, and quantile-quantile plots are simple to make with lattice, it is challenging to combine these simple plots into more complex plots or to plot data from multiple data sources. Splitting data into subgroups and either overlaying with multiple colors or separating into sub-plots (facets) is easy, but the labeling of such plots is not as convenient (and takes more space) than the equivalent plots made with ggplot2. And in our experience, students generally find the look of ggplot2 graphics more appealing.
On the other hand, introducing
ggplot2 into a first course is challenging. The syntax tends to be more verbose, so it takes up more of the limited space on projected images and course handouts. More importantly, the syntax is entirely unrelated to the syntax used for other aspects of the course. For those adopting a “Less Volume, More Creativity” approach, ggplot2 is tough to justify.ggformula: The third-and-a half way
Danny Kaplan and I recently introduced
ggformula, an R package that provides a formula interface to ggplot2 graphics. Our hope is that this provides the best aspects of lattice (the formula interface and lighter syntax) and ggplot2 (modularity, layering, and better visual aesthetics).For simple plots, the only thing that changes is the name of the plotting function. Each of these functions begins with
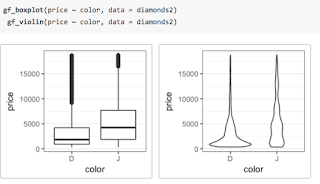
gf. Here are two examples, either of which could replace the side-by-side boxplots made with lattice in the previous post.
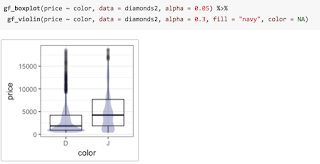
We can even overlay these two types of plots to see how they compare. To do so, we simply place what I call the “then” operator (
%>%, also commonly called a pipe) between the two layers and adjust the transparency so we can see both where they overlap.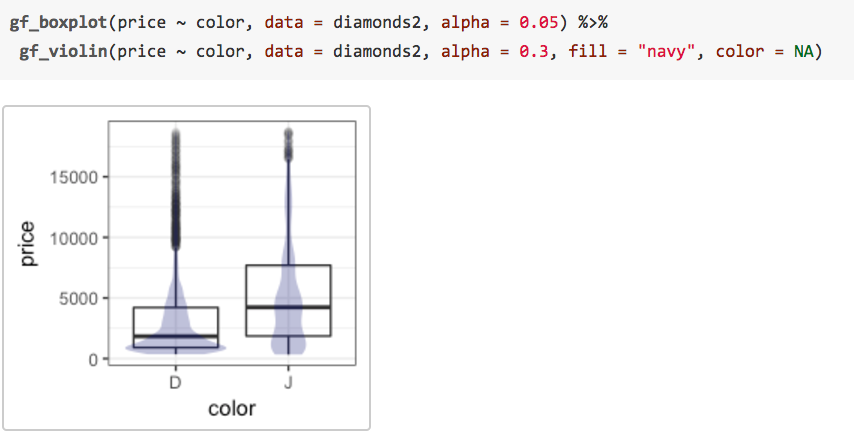
Comparing groups
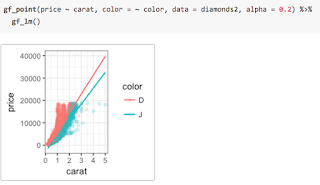
Groups can be compared either by overlaying multiple groups distinguishable by some attribute (e.g., color)

or by creating multiple plots arranged in a grid rather than overlaying subgroups in the same space. The
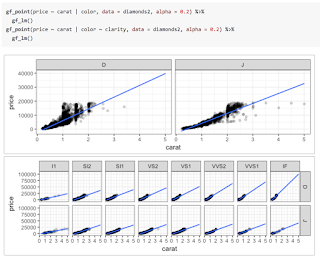
ggformula package provides two ways to create these facets. The first uses | very much like lattice does. Notice that the gf_lm() layer inherits information from the the gf_points() layer in these plots, saving some typing when the information is the same in multiple layers.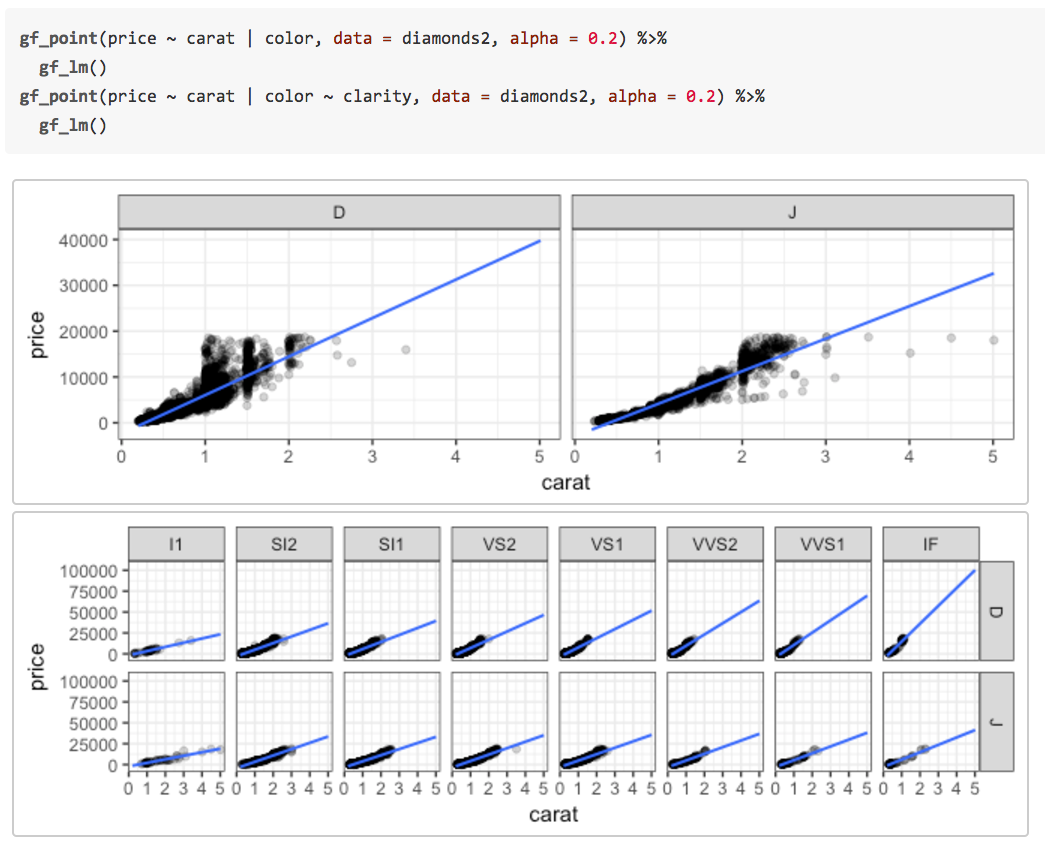
The second way adds facets with
gf_facet_wrap() or gf_facet_grid() and can be more convenient for complex plots or when customization of facets is desired.Fitting into the tidyverse work flow
ggformala also fits into a tidyverse-style workflow (arguably better than ggplot2 itself does). Data can be piped into the initial call to a ggformula function and there is no need to switch between %>% and + when moving from data transformations to plot operations.
Summary
The “Less Volume, More Creativity” approach is based on a common formula template that has served well for several years, but the arrival of
ggformula strengthens this approach by bringing a richer graphical system into reach for beginners without introducing new syntactical structures. The full range of ggplot2 features and customizations remains available, and the ggformula package vignettes and tutorials describe these in more detail.— Randall Pruim
Amusement park attendance (could Wikipedia be wrong?!?)
How do the North American amusement parks compare in popularity? If this question was to come up during a lunch discussion, I bet someone would pull out their smartphone and go to Wikipedia for the answer. But is Wikipedia the definitive answer – how can we tell if Wikipedia is wrong? […]
The post Amusement park attendance (could Wikipedia be wrong?!?) appeared first on SAS Learning Post.
WUSS 2017: The Papers
The Western Users of SAS Software 2017 conference is coming to Long Beach, CA, September 20-22. I have been to a lot of SAS conferences, but WUSS is always my favorite because it is big enough for me to learn a lot, but small enough to be really friendly. If you come I hope you […]![]()
Choose Your SAS Interface
A while back, I wrote about the proliferation of interfaces for writing SAS programs. I am reposting that blog here (with a few changes) because a lot of SAS users still don’t understand that they have a choice. These days SAS programmers have more choices than ever before about how to run SAS. They can […]![]()
How to learn from The Dream Team of experts at Analytics Experience 2017…even if you’re not going
You might not know it by looking at me (I’m rounding up when I tell people I’m 5’8”) but I’m a huge basketball fan. I’ve been following the sport since I was 10, coaching it for the last decade and playing on teams throughout my life, still dedicating my winters […]
The post How to learn from The Dream Team of experts at Analytics Experience 2017…even if you’re not going appeared first on SAS Learning Post.