Here is a method for using SAS and Bing Maps:Signed up for a key on Bing Maps API. Create a basic key and copy it somewhere. I will demonstrate it in the SAS code as [BINGKEY] since I cannot share mine publicly: https://www.bingmapsportal.com/ Use the …
Category: SAS
Your "2013" Top Ten
It’s nearing the end of the year so I thought I’d publish a list of the ten most viewed articles published this year. Like last year, I realised that this would be skewed in favour of older articles. So, in an effort to bring balance, I decid…
NOTE: Have You Won Yet?
Are you checking the SAS advent calendar daily, and entering the prize draw? Have you won anything yet? I have not, but I did win a very informative book a couple of years ago. Opening the windows in the advent calendar is an annual treat. Last year …
Providing User Access to the SAS® BI Lineage Plug-in
I was asked yesterday whether it was possible to use the SAS® Management Console BI Lineage plug-in to provide non-administrators with the ability to review BI Lineage scans (as previously run by administrators). The BI Lineage plug-in can be used to do impact analysis for BI content (reports, information maps etc.) in a similar way […]
Regression Tests, Holding Their Value
Last week I wrote about how our test cases should be considered an asset and added to an ever growing library of regression tests. I had a few correspondents ask how this could be the case when their test cases would only work with specific data; the s…
just been to sas professionals road show in the new sas office in London
A couple of days ago I attended a sas professionals (http://www.sasprofessionals.net/) event focusing on sas V9.4 which is due to be launched in Europe in January 2014 (with statistics 12.3, 13.1 to follow towards the end of the year) . As usual there is so much new terminology to learn and new paradigms to get one’s head around. Naturally I concentrated on what really interests me – Analytics. But there are some non-analytics things that might interest analysts such as myself:
- Sas has significantly hardened the security
2. There are a few new ODS destinations that are aimed at the mobile device world. But the one that is to me the game changer is the ODS to MS PowerPoints completing the suit of preferred delivery platforms. Let me spell this out a good sas programmer can create automatically sleek pdfs, excels, PowerPoints. Now it all can also be ziped automatically with an ods option.
- Sas has introduced two new scripting languages: FedSQL and DS2. The latter, DS2, is something every sas programmer who respect his-self should know. It harks back to the AF object oriented SCL (oh the good old days) so sas dinosaurs like my self will feel at home. The power, according to the presenters, is the ability to truly harness parallel programming and code objects that a truly portable to other environments. We are just facing a case where we could have benefited for the latter feature – we created an amazing solution and now the client wants the beautiful data steps dumbed down to SQL. In the new world we can just hand over the DS2 and it will work as is in say Oracle.
- The IT oriented people will be thrilled with the new embedded web-server (save some licencing money there) and the shinny new sas environment manager
On the analytics side the most interesting development I noted was the High Performance procedures. They are designed for MPP environments doing true parallel-in-memory processing. They come in bundles focusing on: statistics, econometrics, optimisation, data mining, text mining, forecasting. It seems that the re-written engines also perform significantly better on SNP environments (you know the pcs and servers we are using). In essence the technology uses the hardware better than ever as long as you have more than one core and a enough memory assigned to you. A small, but useful, HPxxx procs will be included in sas base if one licences other statistically oriented packages (stat, or, ets, miner …) . It would be interesting to stress test them on a SNP environment and figure out the optimal settings.
It seems to me that most of the new features that were discussed for the EM 12.3 are features that were there in 2.0 till 4.0 but disapeared in the move to the thin client in 5.0 such as Enhanced control over Decision Trees. A new and interesting additions is the Survival data mining introducing time varying covariates.
I will defiantly have to look deeper into
- Sas Contextual Analysis
- Recommendation engine
One interesting observation is the not many chose to go to the analytics session but to the BI and Enterprise Guide ones. Am I of a dying kind? Or is it that all the sas statistical programmers are so busy they do not have time to come to events such as this?
SAS Proc Groovy in Action: JSON File Processing
Last year I took a bite of the newly SAS Proc Groovy to read JSON data since there was no direct “proc import” or “infile” or “libname” way to play with JSON. Here is an nice example from SAS official blog, by Falko Schulz where Proc Groovy is used to parse Twitter JSON file: How […]
An alternative way to use SAS and Hadoop together
The challenges for SAS in Hadoop
For analytics tasks on the data stored on Hadoop, Python or R are freewares and easily installed in each data node of a Hadoop cluster. Then some open source frameworks for Python and R, or the simple Hadoop streaming would utilize the full strength of them on Hadoop. On the contrary, SAS is a proprietary software. A company may be reluctant to buy many yearly-expired licenses for a Hadoop cluster that is built on cheap commodity hardwares, and a cluster administrator will feel technically difficult to implement SAS for hundreds of the nodes. Therefore, the traditional ETL pipeline to pull data (when the data is not really big) from server to client could be a better choice for SAS, which is most commonly seen on a platform such as Windows/Unix/Mainframe instead of Linux. The new PROC HADOOP and SAS/ACCESS interface seem to be based on this idea.
Pull data through MySQL and Sqoop
Since SAS 9.3M2, PROC HADOOP can bring data from the cluster to the client by its HDFS statment. However, there are two concerns: first the data by PROC HADOOP will be unstructured out of Hadoop; second it is sometimes not necessary to load several GB size data into SAS at the beginning. Since Hadoop and SAS both have good connectivity with MySQL, MySQL can be used as an middleware o communicate them, which may ease the concerns above.
On the Cluster
The Hadoop edition used for this experiment is Cloudera’s CDH4. The data set,
purchases.txt is a tab delimited text file by a training course at Udacity. At any data node of a Hadoop cluster, the data transferring work should be carried out.MySQL
First the schema of the target table has to be set up before Sqoop enforces the
insert operations.# Check the head of the text file that is imported on Hadoop
hadoop fs -cat myinput\purchases.txt | head -5
# Set up the database and table
mysql --username mysql-username --password mysql-pwd
create database test1;
create table purchases (date varchar(10), time varchar(10), store varchar(20), item varchar(20), price decimal(7,2), method varchar(20));Sqoop
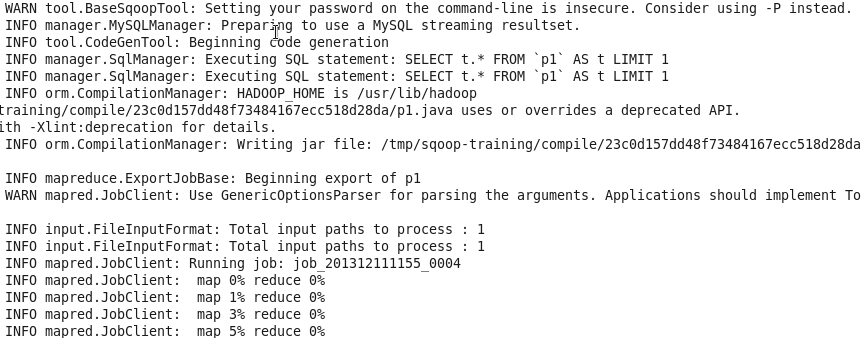
Sqoop is a handy tool to transfer bulk data between Hadoop and relational databases. It connects to MySQL via JDBC and automatically creates MapReduce functions with some simple commands. After MapReduce, the data from HDFS will be persistently and locally stored on MySQL.
# Use Sqoop to run MapReduce and export the tab delimited
# text file under specified directory to MySQL
sqoop export --username mysql-username --password mysql-pwd \
--export-dir myinput \
--input-fields-terminated-by '\t' \
--input-lines-terminated-by '\n' \
--connect jdbc:mysql://localhost/test1 \
--table purchasesOn the client
Finally on the client installed with SAS, the PROC SQL’s pass-through mechanism will empower the user to explore or download the data stored in MySQL at the node, which will be free of any of the Hadoop’s constraints.
proc sql;
connect to mysql (user=mysql-username password=mysql-pwd server=mysqlserv database=test1 port=11021);
select * from connection to mysql
(select * from purchases limit 10000);
disconnect from mysql;
quit;