If you want to learn R, or improve your current R skills, join me for two workshops that I’m offering through Revolution Analytics in January and April. If you already know another analytics package, the workshop, Intro to R for … Continue reading →![]()
Category: SAS
Test Cases, an Investment
It never ceases to frustrate and disappoint me when I hear people talking of test cases as use-once, throwaway artefacts. Any team worth its salt will be building a library of tests and will see that library as an asset and something worth investing in…
‘Tis the Season of Lists
December is the time when the media industry tends to offer more lists than the other 11 months of the year. One that caught my eye was the TIME magazine Top 10 gadgets of 2013. These kind of lists are always good for spurring conversation down the pub…
PROC PLS and multicollinearity
Multicollinearity and its consequences
Multicollinearity usually brings significant challenges to a regression model by using either normal equation or gradient descent.
1. Invertible SSCP for normal equation
According to normal equation, the coefficients could be obtained by %5E%7B-1%7DX'y) . If the SSCP turns to be singular and non-invertible due to multicollinearity, then the coefficients are theoretically not solvable.
. If the SSCP turns to be singular and non-invertible due to multicollinearity, then the coefficients are theoretically not solvable.
2. Unstable solution for gradient descent

The gradient descent algorithm seeks to use iterative methods to minimize residual sum of squares (RSS). For example, as the plot above shows, if there is strong relationship between two regressors in a regression, many possible combinations of  and
and  lie along a narrow valley, which all corresponds to the minimal RSS. Thus can be negative, positive or even zero, which becomes a confounding effect with respect to a stable model.
lie along a narrow valley, which all corresponds to the minimal RSS. Thus can be negative, positive or even zero, which becomes a confounding effect with respect to a stable model.
Partial Least Squares v.s. Principle Components Regression
The most direct way to deal with multicollinearity is to break down the regressors and construct new orthogonal variables. PLS and PCR are both dimension reduction methods that eliminate multicollinearity. The difference is that PLS also implements the response variable to select the new components. PLS is particularly useful in answering questions with multiple response variables. The PLS procedure in SAS is a powerful and flexible tool applying either PLS or PCR. One book, An Introduction to StatisticalLearning, suggests PCR over PLS.
While the supervised dimension reduction of PLS can reduce bias, it also has the potential to increase variance, so that the overall benefit of PLS relative to PCR is a wash.
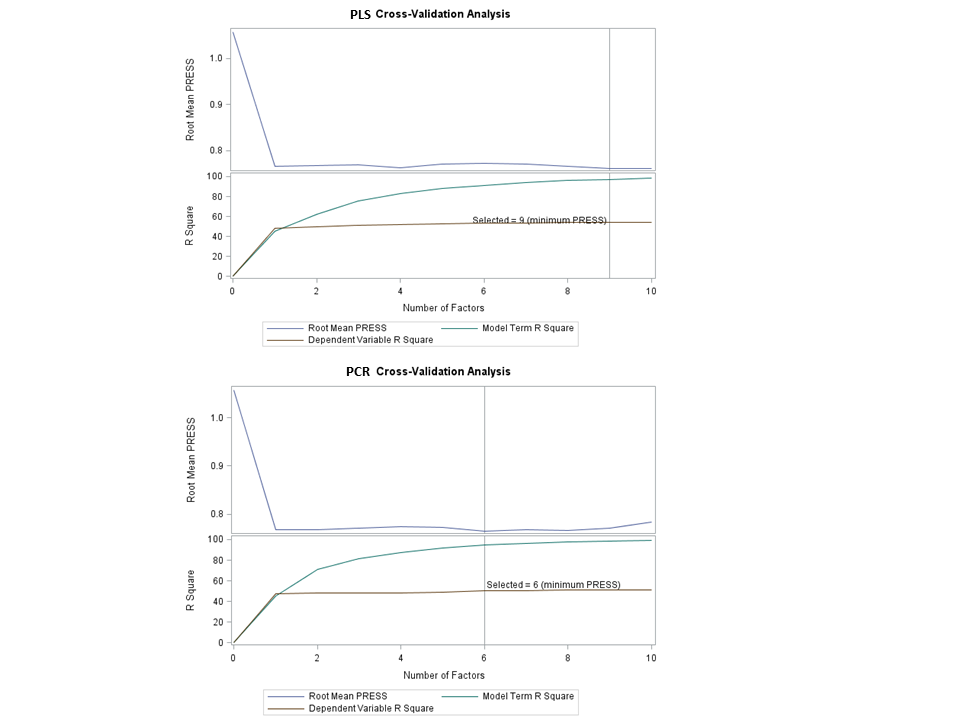
In the example using the baseball data set below, with 10-fold cross-validation, PLS chooses 9 components, while PCR picks out 5.
filename myfile url 'https://svn.r-project.org/ESS/trunk/fontlock-test/baseball.sas';
%include myfile;
proc contents data=baseball position;
ods output position = pos;
run;
proc sql;
select variable into: regressors separated by ' '
from pos
where num between 5 and 20;
quit;
%put ®ressors;
data baseball_t;
set baseball;
logsalary = log10(salary);
run;
proc pls data=baseball_t censcale nfac=10 cv=split(10);
title 'partial least squares';
model logsalary=®ressors;
run;
proc pls data=baseball_t censcale method = pcr nfac=10 cv=split(10);
title 'princinple components regression';
model logsalary=®ressors;
run;NOTE: Reverse-Engineering Technical Debt
I wrote a couple of items about technical debt back in November (here and here). Sometimes you don’t choose to create debt for yourself, sometimes it’s inherited. In technical guises, debt can be inherited when teams merge, for instance.In such circums…
Removing Custom Task Capability Metadata
Yesterday I saw a question on the SAS® Communities site from Nick about Registering Custom Tasks and managing the capability metadata that’s used for role based access control on those custom tasks. I found Nick’s question especially interesting because we have some free Metacoda Custom Tasks and those techniques can also be used to control […]
Use R in Hadoop by streaming
It seems that the combination of R and Hadoop is a must-have toolkit for people working with both statistics and large data set.
An aggregation example
The Hadoop version used here is Cloudera’s CDH4, and the underlying Linux OS is CentOS 6. The data used is a simulated sales data set form a training course by Udacity. Format of each line of the data set is: date, time, store name, item description, cost and method of payment. The six fields are separated by tab. Only two fields, store and cost, are used to aggregate the cost by each store.
A typical MapReduce job contains two R scripts: Mapper.R and reducer.R.
Mapper.R
# Use batch mode under R (don't use the path like /usr/bin/R)
#! /usr/bin/env Rscript
options(warn=-1)
# We need to input tab-separated file and output tab-separated file
input = file("stdin", "r")
while(length(currentLine = readLines(input, n=1, warn=FALSE)) > 0) {
fields = unlist(strsplit(currentLine, "\t"))
# Make sure the line has six fields
if (length(fields)==6) {
cat(fields[3], fields[5], "\n", sep="\t")
}
}
close(input)Reducer.R
#! /usr/bin/env Rscript
options(warn=-1)
salesTotal = 0
oldKey = ""
# Loop around the data by the formats such as key-val pair
input = file("stdin", "r")
while(length(currentLine = readLines(input, n=1, warn=FALSE)) > 0) {
data_mapped = unlist(strsplit(currentLine, "\t"))
if (length(data_mapped) != 2) {
# Something has gone wrong. However, we can do nothing.
continue
}
thisKey = data_mapped[1]
thisSale = as.double(data_mapped[2])
if (!identical(oldKey, "") && !identical(oldKey, thisKey)) {
cat(oldKey, salesTotal, "\n", sep="\t")
oldKey = thisKey
salesTotal = 0
}
oldKey = thisKey
salesTotal = salesTotal + thisSale
}
if (!identical(oldKey, "")) {
cat(oldKey, salesTotal, "\n", sep="\t")
}
close(input)Testing
Before running MapReduce, it is better to test the codes by some linux commands.
# Make R scripts executable
chmod w+x mapper.R
chmod w+x reducer.R
ls -l
# Strip out a small file to test
head -500 purchases.txt > test1.txt
cat test1.txt | ./mapper.R | sort | ./reducer.RExecution
One way is to specify all the paths and therefore start the expected MapReduce job.
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.1.1.jar
-mapper mapper.R –reducer reducer.R
–file mapper.R –file reducer.R
-input myinput
-output joboutputOr we can use the alias under CDH4, which saves a lot of typing.
hs mapper.R reducer.R myinput joboutput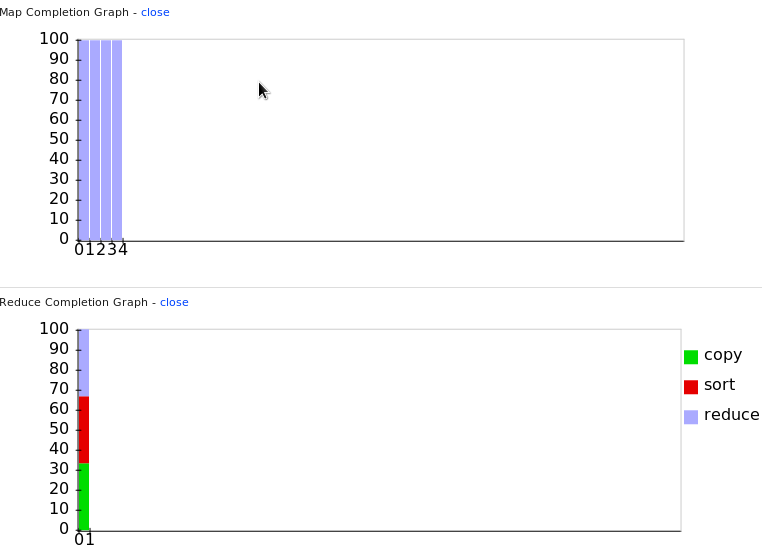
Overall, the MapReduce job driven by R is performed smoothly. The Hadoop JobTracker can be used to monitor or diagnose the overall process.
Rhadoop or streaming?
RHadoop is a package developed under Revolution Alytics, which allows the users to apply MapReduce job directly in R and is surely a much more popular way to integrate R and Hadoop. However, this package currently undergoes fast evolution and requires complicated dependency. As an alternative, the functionality of streaming is embedded with Hadoop, and supports all programming languages including R. If the proper installation of RHadoop poses a challenge, then streaming is a good starting point.
Market trend in advanced analytics for SAS, R and Python
Disclaimer: This study is a view on the market trend on demand of advanced analytics software and their adoptions from the job market perspective, and should not be read as a conclusive statement on what is all happening there. The findings should…