A while back, I wrote about the proliferation of interfaces for writing SAS programs. I am reposting that blog here (with a few changes) because a lot of SAS users still don’t understand that they have a choice. These days SAS programmers have more choices than ever before about how to run SAS. They can […]![]()
How to learn from The Dream Team of experts at Analytics Experience 2017…even if you’re not going
You might not know it by looking at me (I’m rounding up when I tell people I’m 5’8”) but I’m a huge basketball fan. I’ve been following the sport since I was 10, coaching it for the last decade and playing on teams throughout my life, still dedicating my winters […]
The post How to learn from The Dream Team of experts at Analytics Experience 2017…even if you’re not going appeared first on SAS Learning Post.
Where do hurricanes strike Florida? (110 years of data)
With Hurricane Irma recently pummeling pretty much the entire state of Florida, I got to wondering where past hurricanes have hit the state. Let’s get some data, and figure out how to best analyze it using SAS software! I did a bit of web searching, an…
Algorithmic pricing with Redis

The algorithmic pricing is an exciting new area, and it combines engineering and mathematics. Chen’s paper has introduced the algorithmic pricing on Amazon Marketplace. This post is to discuss the implementation of an algorithmic pricing based on Redis from the perspective of the sellers.
The background
- Each of Amazon’s ASINs will have many sellers that compete each other.
- Amazon has a ranking mechanism for Buy Box, say, to punish a new seller. But for the same ASIN, the seller who has the lowest price usually wins the Buy Box.
- For each ASIN, each of many sellers will have an optimal price (the price they want to sell) and a lowest acceptable price (they cannot sell if the price is below it).
- Amazon allows a seller to change price for an ASIN every 15 minutes.
- Why 15 minutes? Because Amazon said that it takes up to 15 minutes for all systems to converge to the new price. But it is not exactly true. Amazon MWS uses 4 data centers in North America and data synchronization is not that fast for each of the databases or each of the data centers.
- Amazon MWS has APIs. But don’t rely on it, and build your own crawlers and price adjustor. The reasons are explained later.
- The sellers’ target variables are mainly
- Buy Box take-over percentage (how they beat the other competitors)
- Profit margin (the higher prices they sell goods at, the better)
How an algorithmic pricing engine works
The overall infrastructure may include three parts.

1. The distributed crawler
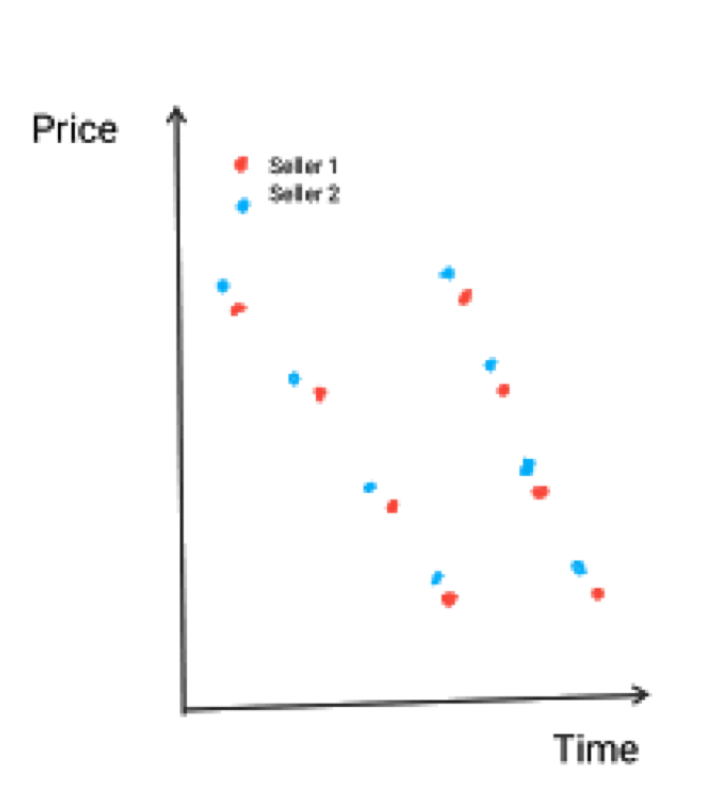
Amazon most time allows a crawler running 1 QPS/IP. But all the data centers and all ASINs from the seller and his competitors have to be closely watched. So a distributed approach will be safer. The response time will be crucial to decide which one is the winner within the game. In a common chasing diagram below, clearly Seller 1 has the upper hand and Seller 2 is losing the group, since the crawler from Seller 1 is faster.
2. The algorithm core
The embedded algorithm will have two purposes
- Analyze the data from the crawler and detect other competitors’ optimal price/lowest acceptable price and strategy.
- Adjust price according to an algorithm. The strategy can be either as simple as “minus one cent from the current competitor’s price”, or as complicated as machine learning or deep learning.
3. The price adjustor
The computed price will enter Amazon and become effective. Amazon will rank lower for the sellers whom he thinks doing algorithmic pricing. Sometimes Amazon even bans the seller. So don’t let Amazon to find that a computer is manipulating its APIs. To emulate human’s behavior on a browser, the two options are phantom.js and headless Chrome.
The role of Redis
Redis is a in-memory data store, which supports persistence and sharding. The first usage for this algorithmic pricing engine is that it can be used as a centralized task scheduler for the crawlers. Besides that, some other interesting fields in algorithmic pricing could be explored and utilized with Redis.
1. Predicative pricing
Redis as a cache has support for TTL(time to live). With the accumulation of the data, the competitors’ price changing time could be predicted. In the publisher-subscriber model, each time the predicted duration for next price changing can be inputted as an expiring key with TTL. Once the key expires, the publisher dispatches a crawling task and makes the price adjustment. The good thing for this approach is that the crawlers don’t need to tap a single web page from Amazon every second that brings the risk of being banned.
+--------------------+
| Subscriber |
+--------------------+
| |
| + psubscribe():void| +--------------+
| | | PubSub |
+--------------------+ +--------+-----+
^
|
+--------------------------------+-----+
| Publisher |
+--------------------------------------+
| |
| + calculateNextTTL():int |
| + onPMessage():void |
| + dispatchCrawler():boolean |
| |
+--------------------------------------+
2. Cross-data-center hedging
The synchronization mechanism across the data centers costs time sometimes hours. That is the reason why we see different prices at different IPs of Amazon at the same time. People will also have different purchasing behavior pattern at different time. Since a seller has the option to change price at a specified data center with IP instead of domain name, it will be an interesting topic to utilize the cool down time for the price to spread to the overall network and make a hedging. Redis’ capacity to keep all prices as hashes in memory will be helpful to spot those valuable occasions.

INSET in Proc SGPLOT
INSET “Mean of the best percent change = &pmean.” / position = bottomleft;Example: Click Here and Here
Using FILENAME ZIP and FINFO to list the details in your ZIP files
It’s time to share another tip about working with ZIP files in SAS. Since I first wrote about FILENAME ZIP to list and extract files from a ZIP archive, readers have been asking for more. Specifically, they want additional details about the files that are contained in a ZIP, including […]
The post Using FILENAME ZIP and FINFO to list the details in your ZIP files appeared first on The SAS Dummy.