In this post, I show a trick to do moving average calculation (can be extended to other operations requiring windowing functions) that is super fast.
Often, SAS analysts need to conduct moving average calculation and there are several options by the order of preference:
1. PROC EXPAND
2. DATA STEP
3. PROC SQL
But many sites may not licensed SAS/ETS to use PROC EXPAND and doing moving average in DATA STEP requires some coding and is error prone. PROC SQL is a natural choice for junior programmers and in many business cases the only solution, but SAS’s PROC SQL lacks windowing functions that are available in many DBs to facilitate moving average calculation. One technique people usually use is CROSS JOIN, which is very expensive and not a viable solution for even medium sized data set. In this post, I show a trick to do moving average calculation (can be extended to other operations requiring windowing functions) that is super fast.
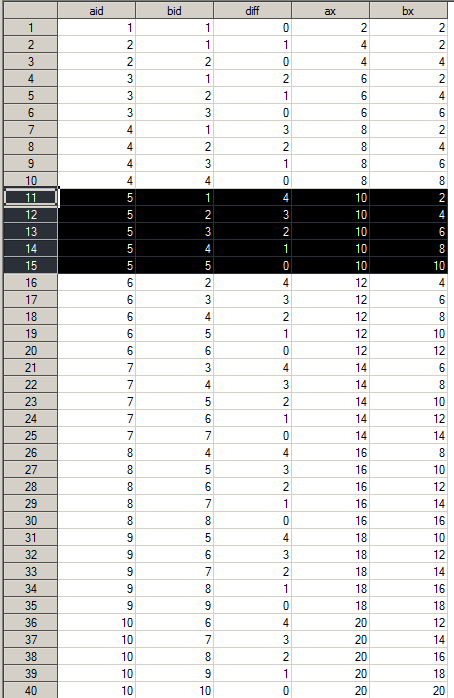
Consider the simplest moving average calculation where the trailing K observations are included in the calculation, namely MA(K), here we set K=5. We first generate a 20 obs sample data, where variable ID is to be used for windowing and the variable X is to be used in MA calculation, and then we apply the standard CROSS JOIN to first examine the resulting data, Non-Grouped, just to understand how to leverage the data structure.
%let nobs=20;
%let ndiff=-5;
data list;
do id=1 to &nobs;
x=id*2;
output;
end;
run;
options notes;
options fullstimer;
proc sql;
create table ma as
select a.id as aid, b.id as bid, a.id-b.id as diff, a.x as ax, b.x as bx
from list as a, list as b
where a.id>=b.id and (a.id-b.id)<= abs(&ndiff)-1
having aid-bid>=(&ndiff+1)
order by aid, bid
;
quit;
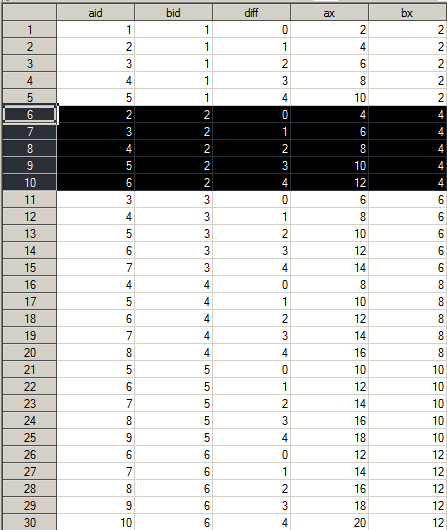
From the resulting data set, it is hard to find a clue, now let’s sort by “bid” column in this data set:
From this sorted data, it is clear that we actually don’t have to CROSS JOIN the whole original data set, but instead, we can generate an “operation” data set that contains the difference value, and let the original data set CROSS JOIN with this much smaller “operation” data set, and all the data we need to use for MA calculation will be there. Now let’s do it: CROSS JOIN original data with “operation” data, sort by (a.id+ops), which is actually “bid’ in sorted data set;
%let ndiff=5;
data operation;
do ops = 0 to &ndiff by 1;
weight=1;
output;
end;
run;
proc sql;
create table ma2 as
select a.id as aid, b.ops, a.id+b.ops as id2, a.x*b.weight as ax
from list as a, operation as b
order by id2, aid
;
quit;
Note that in above code, it is necessary to have a.x multiply by b.weight so that the data can be inter-leaved, otherwise the same X value from original table will be output and MA calculation will be failed. The explicit weight variable actually adds in more flexibility to the whole MA calculation. While setting it to be 1 for all obs result in a simple MA calculation, assign different weights will help to resolve more complex MA computing, such as giving further observations less weight for a decayed MA. If different K parameter in MA(K) calculations are required, only the operation data set need to be updated which is trivial job. Now the actual code template for MA(K) calculation will be:
%let ndiff=5;
data operation;
do ops = 0 to &ndiff by 1;
weight=1;
output;
end;
run;
proc sql noprint;
select max(id) into :maxid
from list;
quit;
proc sql;
create table ma2 as
select a.id+b.ops as id2, avg(a.x*b.weight) as MA
from list as a, operation as b
group by id2
having id2>=&ndiff
and id2<=&maxid
order by id2
;
quit;
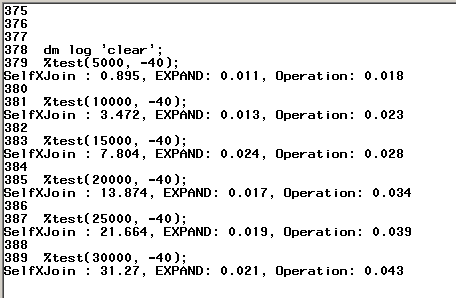
With this new method, it is interesting to compare it to the expensive self CROSS JOIN as well as to PROC EXPAND. On my workstation (Intel i5 3.8Ghz, 32GB memory, 1TB 72K HDD), self CROSS JOIN is prohibitively long in running time (if data is large) while the new method uses only 2X as much time as PROC EXPAND, both time consumptions are trivial comparing to self CROSS JOIN. Time consumption shown below is in “second”.
Below is the code readers can run and compare yourselves.
%macro test(nobs, ndiff);
options nonotes;
data list;
do id=1 to &nobs;
x=id*2;
output;
end;
run;
%let t0 = %sysfunc(time());
options fullstimer;
proc sql;
create table ma as
select a.id, avg(b.x) as ma
from list as a, list as b
where a.id>=b.id and (a.id-b.id)<= &ndiff-1
group by a.id
having id>=abs(&ndiff)
;
quit;
%let t1 = %sysfunc(time());
proc expand data=list out=ma2 method=none;
convert x=ma / transformout=(movave 5);
run;
%let t2 = %sysfunc(time());
%let ndiff=5;
data operation;
do ops = 0 to &ndiff-1 by 1;
weight=1;
output;
end;
run;
proc sql noprint;
select max(id) into :maxid
from list;
quit;
proc sql;
create table ma3 as
select a.id+b.ops as id2, avg(a.x*b.weight) as ma
from list as a, operation as b
group by id2
having id2>=abs(&ndiff)
;
quit;
%let t3 = %sysfunc(time());
%let d1 = %sysfunc(round( %sysevalf(&t1 - &t0), 0.001));
%let d2 = %sysfunc(round( %sysevalf(&t2 - &t1), 0.001));
%let d3 = %sysfunc(round( %sysevalf(&t3 - &t2), 0.001));
%put SelfXJoin : &d1, EXPAND: &d2, Operation: &d3;
options notes;
%mend;
dm log 'clear';
%test(5000, -40);
%test(10000, -40);
%test(15000, -40);
%test(20000, -40);
%test(25000, -40);
%test(30000, -40);

Read more →