Given the friend pairs in the sample text below (each line contains two people who are friends), find the stranger that shares the most friends with me.sample.txtme Alice
Henry me
Henry Alice
me Jane
Alice John
Jane John
Judy Alice
me Mary
Mary Joyce
Joyce Henry
Judy me
Judy Jane
John Carol
Carol me
Mary Henry
Louise Ronald
Ronald Thomas
William Thomas
Thoughts
The scenario is commonly seen for a social network user. Spark has three methods to query such data:
- MapReduce
- GraphX
- Spark SQL
If I start with the simplest MapReduce approach, then I would like to use two hash tables in Python. First I scan all friend pairs and store the friends for each person in a hash table. Second I use another hash table to count my friends’ friends and pick out the strangers to me.
Single machine solution
#!/usr/bin/env python
# coding=utf-8
htable1 = {}
with open('sample.txt', 'rb') as infile:
for l in infile:
line = l.split()
if line[0] not in htable1:
htable1[line[0]] = [line[1]]
else:
htable1[line[0]] += [line[1]]
if line[1] not in htable1:
htable1[line[1]] = [line[0]]
else:
htable1[line[1]] += [line[0]]
lst = htable1['me']
htable2 = {}
for key, value in htable1.iteritems():
if key in lst:
for x in value:
if x not in lst and x != 'me': # should only limit to strangers
if x not in htable2:
htable2[x] = 1
else:
htable2[x] += 1
for x in sorted(htable2, key = htable2.get, reverse = True):
print "The stranger {} has {} common friends with me".format(x,
htable2[x])
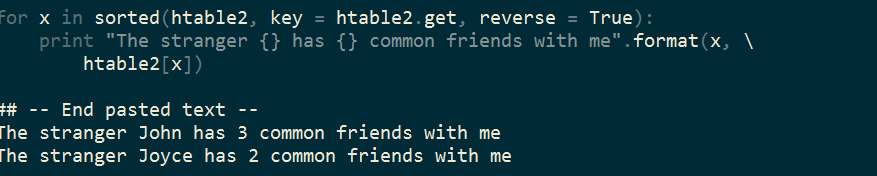
The result shows that John has three common friends like I do, followed by Joyce who has two. Therefore, John will be the one who is most likely to be recommended by the social network.
Cluster solution
If the log file for the friend pairs is quite big, say, like several GB size, the single machine solution is not able to load the data into the memory and we have to seek help from a cluster.
Spark provides the
pair RDD that is similar to a hash table and essentially a key-value structure. To translate the single machine solution to a cluster one, I use the operators from Spark’s Python API including map, reduceByKey, filter, union and sortByKey. #!/usr/bin/env python
# coding=utf-8
import pyspark
sc = pyspark.SparkContext()
# Load data from hdfs
rdd = sc.textFile('hdfs://sample.txt')
# Build the first pair RDD
rdd1 = rdd.map(lambda x: x.split()).union(rdd.map(lambda x: x.split()[::-1]))
# Bring my friend list to local
lst = rdd1.filter(lambda x: x[0] == 'me').map(lambda x: x[1]).collect()
# Build the second pari RDD
rdd2 = rdd1.filter(lambda x: x[0] in lst).map(lambda x: x[1])
.filter(lambda x: x != 'me' and x not in lst)
.map(lambda x: (x, 1)).reduceByKey(lambda a, b: a + b)
.map(lambda (x, y): (y, x)).sortByKey(ascending = False)
# Save the result to hdfs
rdd2.saveAsTextFile("hdfs://sample_output")
# Bring the result to local since the sample is small
for x, y in rdd2.collect():
print "The stranger {} has {} common friends with me".format(y, x)
sc.stop()
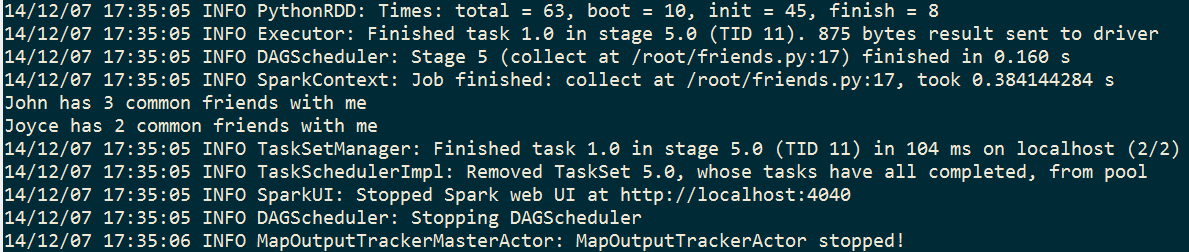
The result is the same. In this experiment, most time is spent on the data loading process from HDFS to the memory. The following MapReduce operations actually costs just a small fraction of overall time. In conclusion, Spark fits well on an iterative data analysis against existing RDD.